LightGBMとは
Light Gradient Boosting Machine の略。機械学習における分析アルゴリズムで、与えられたデータから、目的となる変数を表現する「教師あり学習」と呼ばれる分野のデータ分析方法の1つ。目的変数に応じて、説明変数を「分類」するための手法で、高精度で信頼性が高く、また汎用性も高いことが特徴。マイクロソフトによって2016年頃に開発された。
(読み:ライト・ジービーエム)
「教師あり学習」における手法の1つ
機械学習におけるデータ分析は3種類あります。
- 説明変数(入力データ)と目的変数(出力データ)が揃っており、データの関係から目的変数を予測する「教師あり学習」
- 目的となる変数はなく、一連の入力データからパターンや構造をみつける「教師なし学習」
- データがなく、試行錯誤により精度を高める学習を行う「強化学習」
さらに、教師あり学習の方法として大きく2種類あります。実績から未知の数値を予測する「回帰」と、目的変数に応じて説明変数を適切なグループに分ける「分類」です。回帰の最も代表的な手法が、単回帰・重回帰分析と呼ばれる分析手法で、分類の手法としては、「決定木」という方法が有名です。LightGBMは、決定木の手法の1種類です。
決定木アルゴリズムの進化版
決定木とは、「目的変数」(例:アイスクリームの売上)に影響する「説明変数」(例:曜日、天気、気温)を明らかにして、説明変数の構造を樹木状のモデルとして作成する分析手法のことです。例えば、天気が晴れで、気温が30℃以上で、休日の場合に、アイスクリームがよく売れるなどを構造化します。樹木状で視覚的に把握できるので解釈が簡単という特徴があります。決定木の分岐点となる説明変数の内容や水準は、目的変数を最も高い精度で分類できるように(アイスの売上の差が大きくなるように)設定されます。
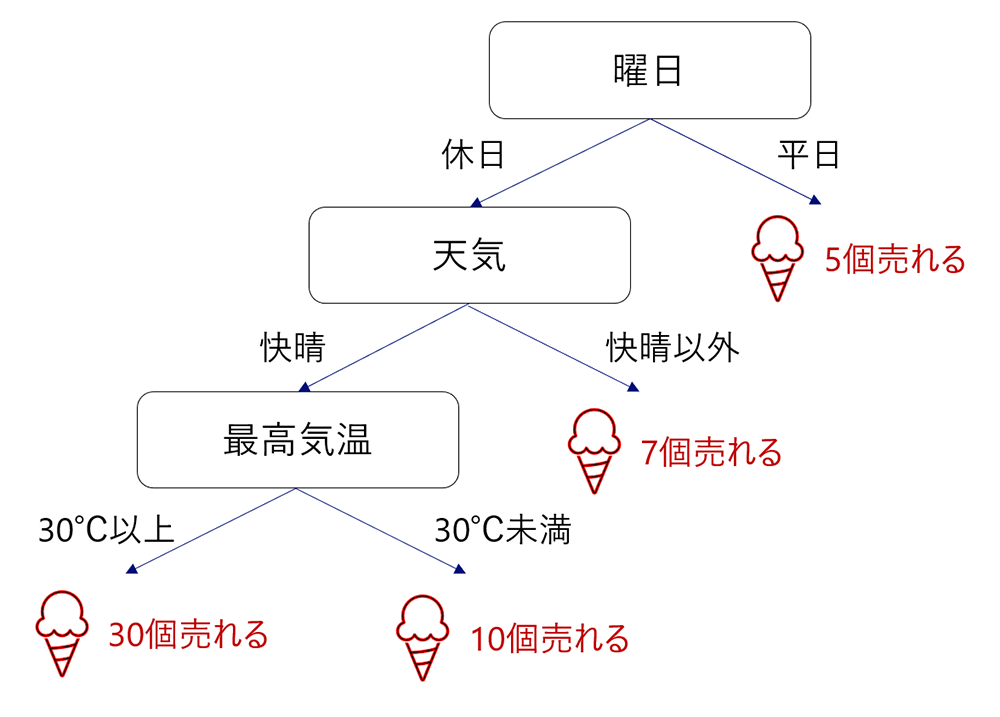
決定木分析を1度実施するだけでは誤差が大きいため、決定木分析を複数回実施することで、分類の精度を高めます。そのための代表的な方法が、学習データを複数に分割する「バギング」という方法です。分割されたデータごとに決定木分析を行い、それぞれの結果を平均することで目的変数を推計します。この方法は「ランダムフォレスト」と呼ばれています。
一方、LightGBMは「勾配ブースティング」という方法を用いて、複数回の決定木分析を行います。
勾配ブースティング
「ブースティング」とは、与えられたデータから決定木分析を行った後に、予測が正しくできなかったデータに重みをつけて、再度、決定木分析を行い、これを繰り返すことで精度を高める方法です。さらに、データに重みづけするのではなく、予測値と実績値の誤差を計算し、誤差を決定木で学習する方法が「勾配ブースティング」です。ブースティングと同様に、誤差に対する学習を繰り返すことで精度を高めていきます。
勾配ブースティングを用いたアルゴリズムとしては、いくつかの方法(XGBoost、Catboost、LightGBMなど)があり、LightGBMはデータ処理が非常に高速化(Light)されたことが大きな特徴です。
LightGBMの特徴
LightGBM(Light Gradient Boosting Machine)は、その名の通り、「Gradient Boosting(勾配ブースティング)」を用いた決定木による機械学習の手法で、「Light(軽い、高速)」なことが特徴です。
勾配ブースティングの場合は、誤差を最小化するように“分割”の要素、基準を見つけるため、データ量に応じて計算量が増えます。1つ1つの決定木の精度をなるべく落とさずに、高速に構築できるようにしたことがLightGBMの最大の特徴なのです。Lightにした工夫としては以下の点があげられます。
①Leaf-wise tree growth
一般的な決定木の場合は、決定木の階層ごとに計算(Level wise)するため、1つの階層の分岐がすべて終わってから次の階層を計算するが、分岐が必要なくなった要素(=葉、leaf)については、それ以上は計算しない。
②Histogram based
決定木の分岐をする際に、すべての値をみるのではなく、ヒストグラムをつくって、数値をまとめて分岐させる。
③Gradient-based One-Side Sampling (GOSS)
学習できていない要素を学ぶことを優先するため、誤差が小さいデータは減らし、誤差の大きいデータだけを残すことで学習データの量を減らす。
④Exclusive Feature Bundling (EFB)
異なる特徴量の中でも、まとめても問題がなさそうな特徴量を1つにすることで計算量を減らす。
また、Python、Rなどのライブラリで提供されているため、誰もが利用できるという特徴もあります。提供されているライブラリでは、予測モデルの要素や影響度をわかりやすく提示されており、分析者以外の理解を促進することができるため、多くの場面で利用されています。
ただし、ハイパーパラメータと言われる変数を事前に設定する必要があります。決定木の「葉の数(num_leaves)」や「1つの葉に含まれる最小データ数(min_data_in_leaf)」、「階層の深さ(max_depth)」などを、モデルの精度と過学習のバランスを考えながらチューニングすることが求められます。
動画で解説
LightGBMに関して動画でお伝えしています。