過学習とは
過学習とは、統計、機械学習において、データの傾向に沿うようにモデルを学習させた結果、学習時のデータに対してはよい精度を出すが、未知データに対しては同様の精度を出せないモデルが構築されてしまうことです。過学習になると、モデルを実運用することが難しくなってしまいます。
過学習は、特定のデータにモデルが過剰に適合(学習)してしまうことによって生じます。モデルを学習する際には、過学習の発生に注意しながら、データ、モデル、学習方法それぞれに対し、それを防ぐよう対処する必要があります。
過学習の確認
過学習が起きているかどうかを確認するためには、学習に使うひと塊のデータを、訓練用とテスト用に分割します。訓練用データで、モデルの学習を行い、テスト用データを疑似的な未知データとして、モデルの評価に使うという方法を行います。
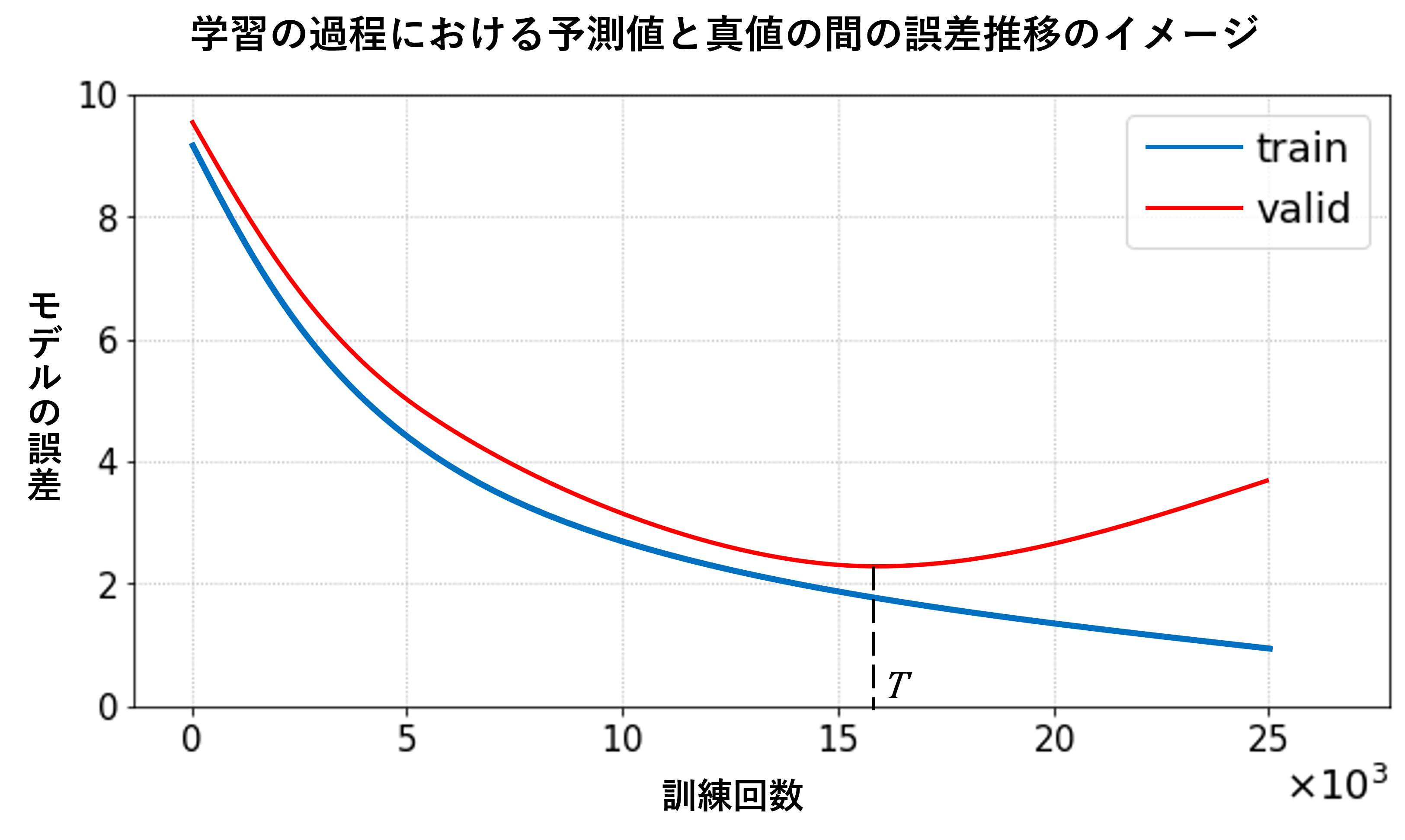
モデルの評価には、通常は予測値と真値の乖離のような評価指標を誤差として定義して、その当てはまり具合を数値的に評価します。訓練用データでの学習における誤差を「訓練誤差」、テスト用データの場合を「汎化誤差」と呼び、一般的には、学習の進みを、訓練回数とその時点の誤差で表した学習曲線として確認します。学習初期では徐々に双方の誤差は小さくなります。しかし、ある時点から、訓練誤差(図中のtrain曲線)は減少を続けますが、汎化誤差(valid曲線)は、増加することがあります。これは、モデルが訓練データへ過剰に適合し始め、未知データであるテストデータでの性能が落ち始めていることを表しています。
ごく簡単な対処法として、このモデルの学習を時点T近辺で止めることで、過学習が抑えられたモデルを得ることができます。
過学習の原因
過学習が起きる原因としては、予測や分類をするうえで、訓練データ中の本質的でないノイズのようなデータにまで、過剰に「合う」ように学習が行われることや、多数の重み係数を少数のデータから決めようとすることが挙げられます。一旦、過学習の傾向が現れると、未知データに対する性能が落ちていくことが生じます。
具体的に過学習が起きる場面を、データ、学習方法、モデルという観点からまとめると以下のようになります。また、これら原因が重複することで、より大きな過学習の傾向を生じることがあります。
| データ |
|
|---|---|
| 学習方法 |
|
| モデル |
|
過学習を防ぐための方法
過学習への簡単な対処方法を紹介します。
データの個数や説明変数を調整する
学習における説明変数や特徴量として不要な情報や項目を事前に除去し、説明変数を減らすことで過学習を防ぐことができます。
交差検証や学習の早期終了を行う
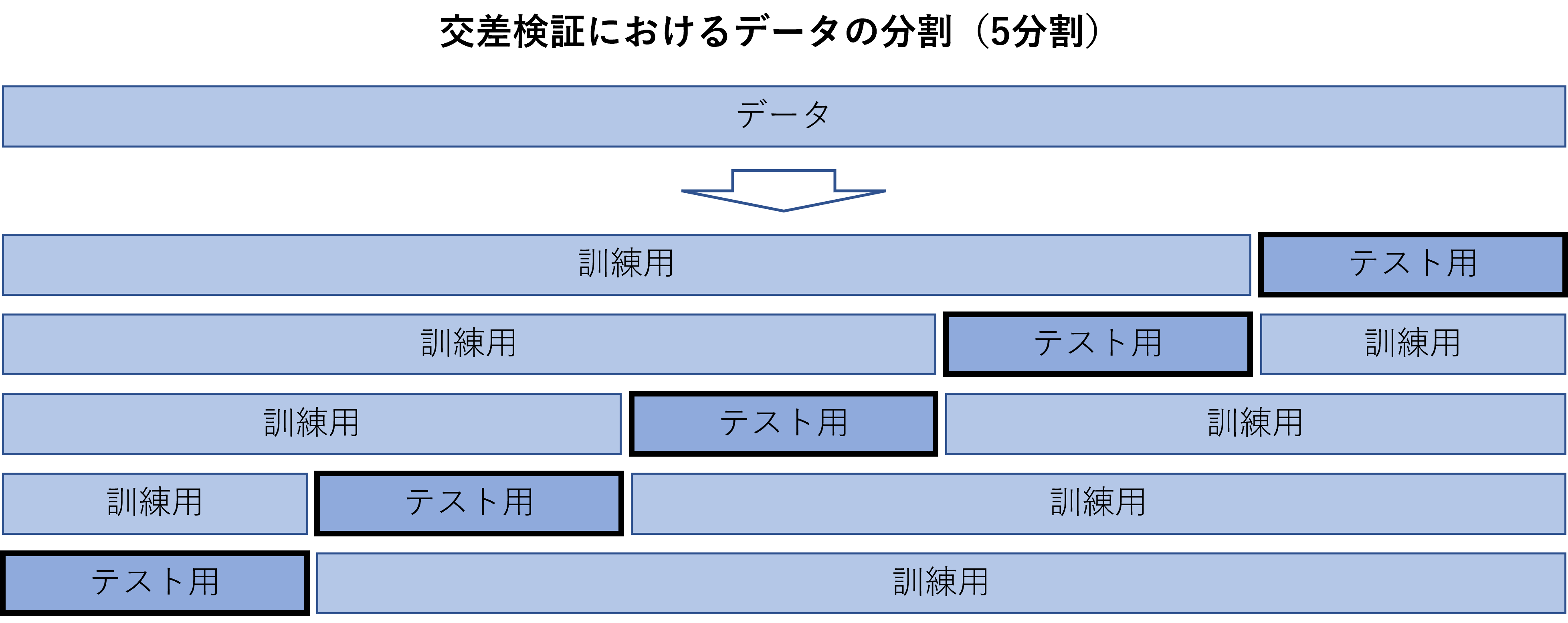
データの一部をテスト用データに分割して、疑似的に未知データを作り出すことは過学習対策の基本です。この分割を複数パターン行うことで、データのさまざまな部分が未知データとなるように工夫する方法を「交差検証」と言います。データをk個に分割したり、状況により複雑な分割を行う場合もあります。学習の途中で、テスト用データに対する性能が向上しなくなった場合に、学習を打ち切ることで、過学習に至る前のモデルを得ることができます。
モデルの単純化
データの件数や項目数に対して、大量のパラメータ(補助の変数)があるようなモデルを利用する場合に過学習が起こることがあります。学習曲線などを見ながら過学習の状況をチェックし、モデルの複雑性を低減されることが求められます。
1つ目は、パラメータの調整により、モデルサイズを小さくする方法です。木系モデルでは、葉数や深さなどを、データのサイズに合わせて小さくなるように調整します。
2つ目は、正則化と呼ばれる方法です。寄与の大きくなる説明変数の数が増えることに対して、罰則のような効果を入れて学習を進めることで、学習プロセスのなかで説明変数を選別し、その数や寄与を小さくします。結果として、当初のアルゴリズムでありながら、モデルを小さくするような効果が働き、過学習を回避することができます。
3つ目は、アンサンブル学習です。学習時にモデルやデータの一部分のみを利用することで、小さいサイズのモデルを多数作り、アンサンブルとして統合する方法です。ランダムに一部のユニットを無効にしながら学習したり、ランダムにサンプリングしたデータからモデルを作る方法などがあります。本来大規模なモデルであるものでもサイズを小さくすることで、複雑性を落とすことができます。
これらの過学習を回避する方法は、データやモデルの条件により、効果が変わってきます。より単純なモデルなどの別のモデルを検討することも一つの選択肢であり、どのようなアプローチをとるかは、個別に判断する必要があります。
動画で解説
過学習に関して動画でお伝えしています。