マシン・アンラーニングとは
マシン・ラーニング(機械学習)とは、コンピューターが自動で学習しルールやパターンを発見する方法であるのに対し、
マシン・アンラーニング(機械非学習)とは、学習済みの機械学習やAIモデルから特定のデータや情報を消すための操作の総称です。
生成AIの開発の競争が激化するなかで、意図せず機密情報や個人情報などのデータが学習データに混ざりこんでしまうことがあります。AIモデルを再学習する必要がありますが、モデルが大規模なため、多額のコストがかかることが懸念されます。そのため、機密情報や個人情報などの特定のデータのことをAIモデルに「忘れさせる」ことが必要になります。モデルの精度を保ちながら、データの一部を除去することができるため、マシン・アンラーニングはAIの健全な社会実装を推進するために注目されています。
大規模化したAIモデルの再学習に関する課題
近年のAIモデルの開発では、より高精度なモデルを構築するためには、取得するデータや計算資源が大規模であるほど望ましいと考えられています。モデルの初期構築に多額のコストが必要となるだけではなく、以下のような点が運用時にも大きな課題となる場合があります。
たとえば、モデルの学習データに権利侵害や有害な不適切なデータが混ざっていることが発覚した場合に、モデルを再構築する必要に迫られるケースなどが考えられます。小規模なAIモデルであれば、不適切データをデータセットから削除し、モデルを即座に修正することが可能でした。しかし、大規模化したAIモデルの運用では、モデルをその都度、再学習することが難しく、また、機械的に収集されたデータを精査することも非現実的なため、その対処の方法が技術的に求められてきました。
知識を消去するための方法
モデルの頻繁な再学習を避けるために、AIに学習させた知識を事後に差分的に操作(消去)する技術が求められます。AIモデルから特定のデータに関わる知識のみ削除するためには、特定のデータのことをAIモデルに「忘れさせる」ことが必要になります。この考え方が、モデルから知識を消す操作であるために「マシン・アンラーニング(機械非学習)」と呼ばれています。
与えられた知識を効率よく学習することに主眼を置いてきた「マシン・ラーニング(機械学習)」とは、逆のコンセプトでありながらも、類似の方法で解決できるように思われます。しかし、AIモデルでは、学習された知識がモデル内部でどのように保持されているかを把握することが難しいため、「忘れさせる」べきデータを特定することが困難です。また、忘れるためのアルゴリズムを適用した結果、モデルの機能や精度を大きく悪化させてしまう可能性もあります。
モデルの精度を維持しながら、知識を消去する方法の研究が盛んに行われていますが、主流となる方式はまだ定まっていません。
忘れたことをどう評価するか
2023年9月には、人工知能研究に関する国際学会であるNeurIPS では、マシン・アンラーニングのコンペティションが開催されました。顔写真から年齢を予測するAIモデルが参加者に与えられ、指定された顔写真画像をAIモデルに忘れさせることが競われました。
「忘れさせる」ことの評価については、あるデータを「忘れさせたモデル」と、そもそもそのデータのことを「知らないモデル」との比較によって行われます。具体的には、図のように、「A+B」のデータセットで学習したAIモデル(与えられたもの)に対して、アンラーニングアルゴリズム(データBについて忘れるように指示)を当てはめたものと、「A」のデータセットだけで学習したAIモデルを比較して評価をしています。
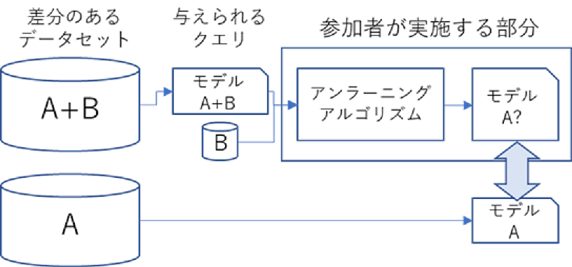
「忘れさせたモデル」(A+BからBを除いたもの)と「知らないモデル」(Aだけ)を比較して、モデル構造が近い状態になる場合を「強い忘却」と呼び、精度や機能が同水準になるだけでモデル構造が近い状態にならない場合を「弱い忘却」と呼びます。「弱い忘却」の場合は、どのようなデータが削除されたかを復元されてしまう、モデルハッキングが行われる可能性があり、「強い忘却」の方が望ましいとされています。
マシン・アンラーニングは、機械学習における新たな概念であり、評価の指標やその手法は多様です。データ除去によるプライバシーの保護、全体を学習させた後で不要な部分だけを除外するという学習サイクルの設計などで、AIモデル構築に関わる重要な技術となることも期待されています。
動画で解説
マシン・アンラーニングに関して動画でお伝えしています。