連合学習とは
分散しているデータを1か所に集めずに、AIモデルを分散している環境に配布しながらセキュアにモデリングする方法のことです。組織を超えたモデルを構築する際に、組織間のデータを直接やり取りすることを避け、モデルを組織間でやり取りすることで、データ利用の高度化とプライバシー保護を同時に解決する方法です。
組織間でのデータ・モデル共有
データサイエンスの結果をビジネスに適切に反映するためには、質・量ともにより良いデータを取得することが欠かせません。いかにデータを取得・整理するかという点での一つのアプローチとして、組織を跨いでデータを集めることにより、多量・高品質のデータを利活用することが期待されています。
組織を跨いでデータの利活用を行うには、データのプライバシー保護を意識した分析技術を意識する必要があります。組織間で暗号化されたデータを共有する方法の「秘密計算」と、モデルを共有する方法である「連合学習」の2つがあります。
秘密計算ではデータに高度な暗号化を施しますが、データの授受が組織間で行われます。一方、連合学習ではデータの直接的な授受を避け、モデルの更新に必要な情報だけを共有するシステムの構築が基本的な考え方となっています。
連合学習の特徴
連合学習は、組織間でのデータの直接的な共有を避けて、一つのモデルを様々な参加者が共同で管理していくAIシステムです。具体的には、連合学習におけるAIモデルの学習プロセスは、下記のようなサイクルで行なわれます。
①初期AIモデルの配布
②クライアント環境でAIモデルの学習を実施
③中央サーバでのAIモデルの更新
④更新されたAIモデルの配布
⑤クライアント環境のAIモデルの更新
連合学習システムにおけるAIモデルの学習プロセス
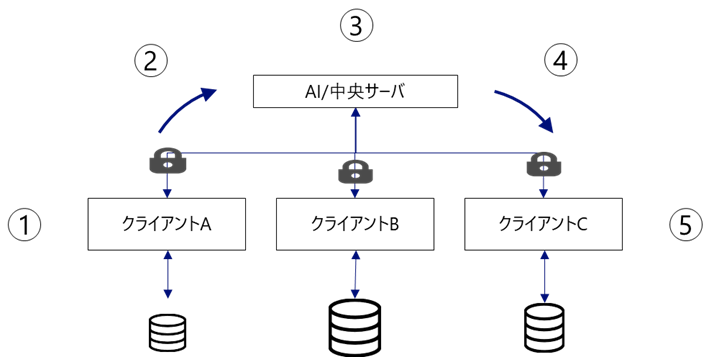
連合学習のプロセスの中で、やり取りされるデータは、生の個人情報や機密データではなく、モデルを更新するために必要な誤差情報(FedSGD)やモデルのパラメータ(FedAVG)となるので、セキュアなモデル構築ができると考えられています。
連合学習の社会への適用
このようなシステムの具体的な適用先としては、金融機関での不正取引の「AI検知」が挙げられます。不正取引検知の業務は複数の金融機関で同様に行なわれていますが、このAIモデルの開発を個々の金融機関で独立に実施すると、不正取引データの数の少なさやデータの偏りによって、モデル開発に支障が生じます。そのため、十分なデータを確保し効率的なモデリングを業界全体で行うために、連合学習のような方法が期待されています。
その他には、保険査定、医療や自動運転などへの事例が見られます。一般的に連合学習は、個々の組織でモデリングに必要なデータ件数が十分でない場合で、かつ組織を跨いだデータの統合でデータの質量が確保されるような状況への適用が有効とされています。
連合学習の課題
広く実装が考えられている連合学習ですが、ITシステム、AIモデル開発、エコシステムとして以下の課題が認識されています。
-
ITシステム:
各クライアントにおいてAI利用の計算環境を構築する必要がある
-
AIモデル開発:
自社データのみを使った場合と比較して精度が落ちる懸念がある
-
エコシステム:
連合学習に参加するメリットが組織のもつデータ量に反比例する
連合学習は、データ分析を高度化する技術として、様々な領域への応用が期待されています。特に社会インフラに近い領域では、業界共通の類似業務のコスト削減が期待されています。その利用にあたっては、技術的課題からシステムの運用課題まで存在しますが、求めるシステムに応じた適切な解決策を選定することで、連合学習の選択肢が広がると予想されます。
動画で解説
連合学習に関して動画でお伝えしています。