ビジネスにおける意思決定には、データに基づいた深い洞察が不可欠です。しかし、日々増大する構造化データに加え、顧客からの問い合わせやSNSの投稿、営業日報といった非構造化データ、とりわけ大量のテキストデータから有益な情報を引き出すことは、多くの企業にとって大きな課題となっています。
近年注目を集める生成AIは、これらの課題を解決する可能性を秘めています。一方で、生成AIをデータ分析の領域で活用するには、特有の課題も存在します。
生成AIが抱えるデータ分析の限界
- 1.ハルシネーション問題:
生成AIの使用は、もっともらしい嘘や事実と異なる内容を生成してしまう「ハルシネーション」のリスクを常に伴います。これは、信頼性が求められるデータ分析において致命的な欠点となり得ます。 - 2.数字への弱さ:
大規模言語モデル(LLM)は、単体では厳密な数値計算を苦手としています。確率的に文章を生成する仕組み上、合算や平均といった基本的な統計処理であっても出力を誤る可能性があります。 - 3.コンテキスト長の限界:
生成AIに大量のデータをそのまま入力することは、入力トークン数の制約(コンテキスト長)により困難です。これにより、データ全体を俯瞰した分析や、膨大なデータの中に散らばる微細な兆候を見つけ出すといった活用が難しくなります。
これらの課題は、生成AI単独でのデータ分析には限界があることを示唆しています。では、どのようにすればこれらの課題を克服し、大量のデータからビジネスインサイトを引き出すことができるのでしょうか?その答えが、AIエージェントを用いた探索的なデータ分析ワークフローにあります。
AIエージェントが拓く、次世代の対話型データ分析
私たちNRIが提供するソリューションは、LLM単独の限界を乗り越え、AIエージェントがデータ基盤にアクセスし、ユーザと対話的に分析を行うことを可能にします。このソリューションの核となるのは、以下のような機能的特長です。
- 1.独自開発APIによる正確な集計と実行
AIエージェントは、NRIが独自に開発した分析用API群と連携して動作します。計算や統計処理をLLM任せにせず、API側で実行することで、生成AI特有のハルシネーション(嘘の生成)や計算ミスを回避し、正確な統計的事実を取得します。 - 2.データカタログ連携による広範な探索
エージェントは社内のデータカタログと連携し、構造化・非構造化を問わず広範なデータにアクセス可能です。これにより、プロンプトの文字数制限(コンテキスト長)に縛られることなく、膨大なデータ資産の中から必要な情報源を特定できます。 - 3.透明性の確保と検証可能性(トレーサビリティ)
エージェントが行った分析プロセスはすべて詳細に記録されます。これにより、分析がブラックボックス化することなく、その過程を検証し、信頼性を確保することが可能です。ユーザは分析のどの段階においても、エージェントの思考プロセスや実行内容を確認し、必要に応じて軌道修正を行うことができます。
自ら考え、深掘りする分析サイクル
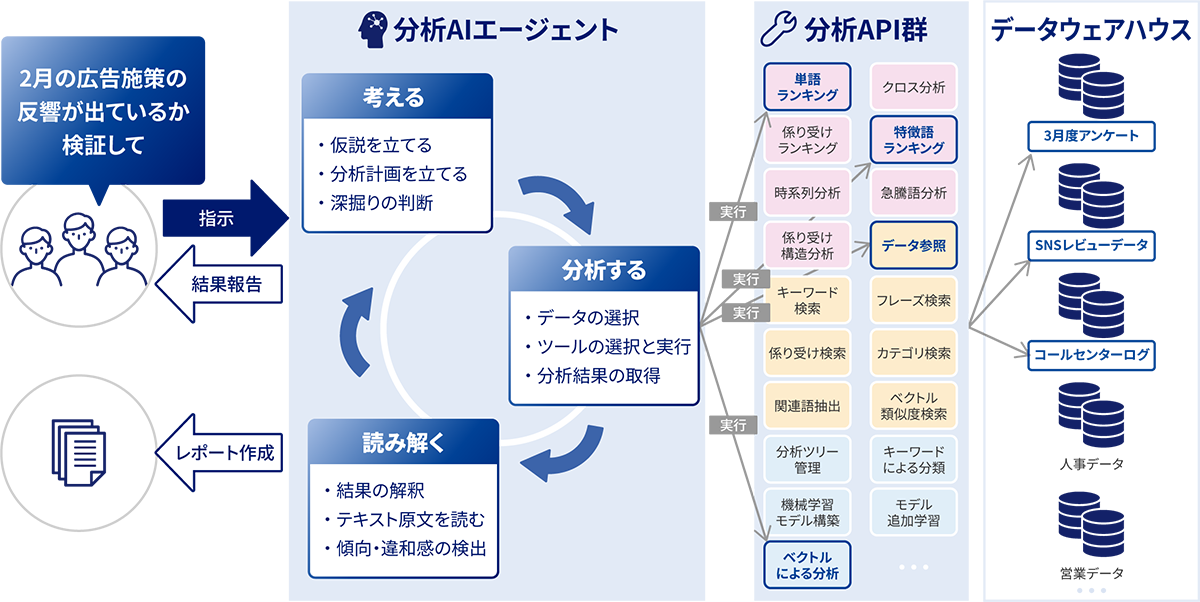
AIエージェントは、図のようなプロセスでデータ分析を遂行します。ユーザは分析の指示や、考慮してほしい観点などの情報をエージェントに与えることで、分析プロセスに介入し、その方向性を柔軟に調整できます。
考える: 仮説を立て、どのような分析が必要かを計画し、深掘りの必要性を判断します。
分析する: 計画に基づき、分析対象のデータを選択し、各種分析ツール(API)を実行して結果を取得します。
読み解く: 分析結果から傾向や違和点を検出します。必要に応じてデータ原文を参照し、要因を深掘りします。
レポートする: 得られた洞察をレポートとして報告します。
まとめ:AIエージェントで、データ分析の未来を切り拓く
AIエージェントを活用した本ソリューションは、生成AIの強みと、統計的・探索的なデータ分析の強みを組み合わせることで、大量の構造化・非構造化データから、これまでにない深いビジネスインサイトを引き出します。ハルシネーションのリスクを低減し、高い計算精度を担保しつつ、コンテキスト長の限界を超えた広範なデータ分析を、ユーザとの対話を通じて自律的に実現します。
ビジネス課題の解決を加速させるAIエージェント×データ分析の力を、ぜひご体験ください。