
2024年の生成AIの展望――生成AIは“試用”から“活用”へ
2022年11月のChatGPT公開を機に勢いがついた生成AIの市場規模は、日本では2030年までに年平均47.2%増で成長し、需要額で約1.8兆円まで拡大すると見られています ※ 。多彩な生成AIソリューションが登場し、企業での導入が進んだ2023年を経て、2024年はどのような変化が起きるのでしょうか。野村総合研究所(NRI)は、生成AIの進展が、製造、金融、流通小売、広告、エンターテインメント、行政といった6つの主要業界の仕事と将来像に与える影響について深掘りして分析しました。本テーマに詳しい未来創発センターの塩崎 潤一、DX基盤事業本部の長谷 佳明、鷺森 崇、NRIデジタルの松崎 陽子に、生成AIの技術進歩やそれに伴う課題、今後の展望について聞きました。
「生成AIパッケージ」と「独自生成アプリケーション」への発展
2023年までは、基盤モデルの性能向上やAI基盤の大規模化が、企業としては生成AIの主なテーマでした。しかし、2024年は、実用的なアプリケーションによる圧倒的な差別化と競争力の向上が実現し、AIの信頼性向上や機能拡張、アプリの生産性向上、セキュリティに関する技術の獲得が必須となるでしょう。生成AIは“試用”から“活用”へシフトしたと言えます。
AI革命の火付け役となったChatGPTには、さまざまな機能が追加されています。2023年7月に提供がはじまった「GPT-4」では入力できるトークン数が増大したほか、外部ファイルの取り込みも可能になりました。さらに同年11月には「GPTs」の提供がはじまり、会話によって独自のアプリケーションを開発するなど、GPTをカスタマイズできるようになりました。これにより特定の作業や対話にチューニングしたGPTを簡単に呼び出せるほか、調整したGPTを公開することで他のユーザーに提供することも可能になりました。
2024年2月にはユーザーとの会話履歴を記憶する「Memory」機能が追加され、テスト運用がはじまりました。この機能により、ChatGPTはユーザーとの対話履歴を参照し、過去の指示内容や、対話結果を利用することができるようになりました。これにより、対話履歴に基づいたChatGPTのパーソナライズ化が実現されています。このような機能の追加により、ChatGPTは単なるチャット用途だけではなく、導入すれば最新の生成AI機能を容易に活用できる「生成AIパッケージ」へと進化しているのです。
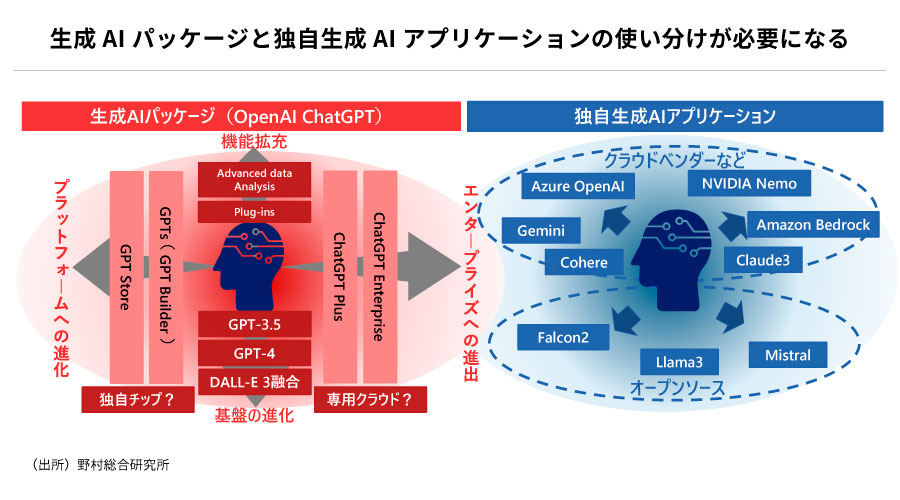
一方で、既存のパッケージ化されたモデルでは実現できない独自性を追求するには、「独自生成モデル」が必要です。こうした背景のもと、事前にトレーニングされたモデルを特定のタスクに合わせて微調整できるファインチューニング(Fine-Tuning)というプロセスに注目が集まっています。最近では「Llama3」や「Mistral」といったオープンソースモデルやクラウドベンダーの技術を使った独自生成AIも立ち上がりはじめています。このようなオープンソースモデルは、ファインチューニングによって出力を独自形式に調整するだけでなく、継続事前学習によって新しい知識を獲得させることも可能であり、業界特化アプリケーションに適しています。またオープンソースモデルはローカルのセキュアな環境で実行できるため、機密情報を扱う企業での活用も期待されています。
状況を理解し、最適な行動をする「AIエージェント」が普及
2024年には生成AIを用いたAIエージェントの活用も進むでしょう。AIエージェントとは、生成AIが、人とデータやAIシステムとの対話の仲介者(エージェント)となり、細かく指示しなくても目標に向けて状況を理解し、最適な行動をする自律型システムです。エージェントを通した対話型UIは将来的にはこのAIエージェントが従来型UIを置き換え、ビジネスや日常生活などさまざまなサービスの入口になりえます。専門性や価値観の異なる複数のAIエージェントがユーザーと各サービスの仲介者となり、ユーザーの希望を適切に解釈しシステムに伝えてくれるのです。
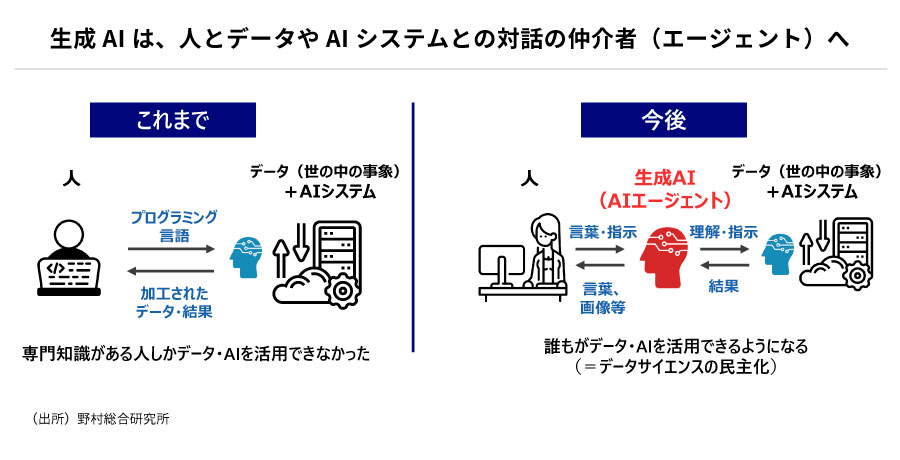
例えば「旅行に行きたい」というような漠然とした目的に対して、ホテルを検索できるAIエージェントと航空チケットを検索できるAIエージェントが対話し、ユーザーの要望に沿った細かい指示をしなくても最適なプランを提案してもらえる時代がやってくるかもしれません。
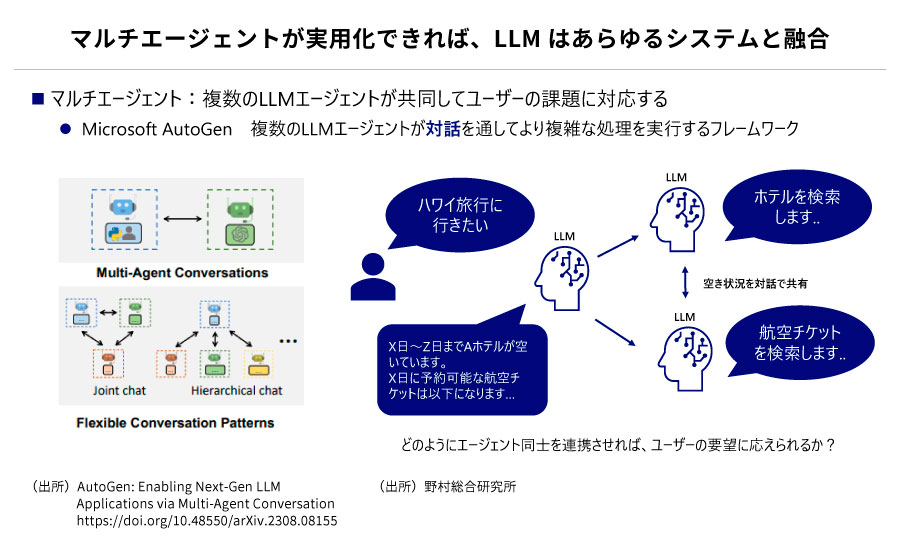
性能向上という観点では、複数のニュートラルネットワークを組み合わせ、モデルを連携させることで性能を向上させるMoE(Mixture of Experts)が活用され始めています。また、AIをネットワーク化し、より高度な回答を導く手法も検討されています。モデル間のやり取りは、機械的なデータの通信に代わり、”言葉”が使われる人間的なシステムになると予想されます。
生成AIはテキスト情報だけでなく、音声や画像、動画も認識できるようになってきています。ECサイトなどでは、テキストや音声のみの情報で与えられた指示に対して、画像をリアルタイムで抽出しながら作業できるようになるでしょう。このような、複数種類のデータを同時に処理するマルチモーダル化は、2024年以降さらに進むと考えられます。
セキュリティやデータ利用の課題にも光が
生成AIが社会に組み込まれていけば、新たな脅威も出てきます。その最たるものは、情報漏えいのリスクです。近年では、生成AIに組み込まれたメモリや開発機能の隙をつく攻撃により、機密情報が流出する事件が発生しています。日本で生成AIの業務活用をさらに拡大するには、こうしたセキュリティへの懸念を拭い去る必要があります。
事実と異なる回答をしてしまうハルシネーションのリスクも、生成AIへの信頼を損なっています。対策として有望視されているのが、RAG(Retrieval-Augmented
Generation:検索拡張生成)と呼ばれる技術です。ユーザーへの回答に必要な知識を外部データから参照することで、ハルシネーションを抑制できるとされています。RAGでは「正確な検索ができるか」が回答の精度を高めるため、通常のキーワード検索に加えて、文意の類似性までを判断できる意味的検索の活用が進んでいます。
生成AIが活用しているデータの中には、メディア各社が発信する情報も含まれています。そのため、AIとメディアの共存についても議論が必要です。昨今では、OpenAIによる記事の取得をブロックする動きがメディアの一部ではじまっています。OpenAIはメディア各社に自らデータ使用料を支払いはじめましたが、豊富な資金を元にしたデータ利用料の支払いや囲い込みが、競合他社の参入を難しくし、AI技術の独占につながるという懸念も高まっています。
こうした懸念への対策として、2024年では、生成AIに関する法規制やガイドライン、データセットの整備、AI標準化に向けた議論も進むでしょう。
生成AIに対する日本人の意識
NRIが2023年10月に行った「生成AI利用に関する就労者調査」によると、日本では生成AIに期待している肯定派の割合は41.8%であり、否定派の22.8%を大きく上回りました。仕事を奪われるという危機感は、日本では低く生成AIに対する期待は強いと考えられます。一方、生成AIに対する不安としては、「個人情報の漏えい」が37.1%、「情報の信頼性」が33.9%などで、プライバシーや悪用についての懸念事項があげられています。
データサイエンティストの世界的コンペティションにおいて、優秀な成績を収めている日本人が多くいることからも、日本は生成AIを浸透・発展させるポテンシャルは高いと言え、今後はさらに加速させていく必要があります。そのためには、メリットを訴求して生活者の期待を醸成するだけでなく、リスクなどの課題も伝えていかなければなりません。期待と課題が両輪となり、生成AIを健全に発展させていくことが大切です。生成AIの発展は、インターネットによる情報革命に並ぶ大転換となるはずです。「ワクワク感」と「覚悟」を持って、時代の転換点に向き合う姿勢が必要となるでしょう。
-
※
一般社団法人 電子情報技術産業協会「生成AI市場の世界需要額見通し」より
https://www.jeita.or.jp/japanese/topics/2023/1221-2.pdf
- NRIジャーナルの更新情報はFacebookページでもお知らせしています
プロフィール
-
塩崎 潤一のポートレート 塩崎 潤一
未来創発センター チーフデータサイエンティスト
筑波大学社会工学類卒業。野村総合研究所入社。入社以来、マーケティングや生活者の価値観、数理解析などを専門分野としてコンサルティング業務を担当。マーケティングサイエンスコンサルティング部長などを経て、2021年にデータサイエンスラボの初代ラボ長就任。
主な著書に「データサイエンティスト入門」、「データサイエンティスト基本スキル84」、「まるわかりChatGPT&生成AI」など。
(社)データサインティスト協会・理事、広島大学「データサイエンティスト養成」非常勤講師(2019年~)、筑波大学「異分野融合型データサイエンティストプログラム」非常勤講師(2023年~)。 -
長谷 佳明のポートレート 長谷 佳明
IT基盤技術戦略室
2014年よりITアナリストとして従事。先進的なIT技術や萌芽事例の調査、コンサルティングを中心に活動中。専門は人工知能、ロボティクス、IT基盤技術など。共著に「AIまるわかり」(日本経済新聞出版社)がある。
-
鷺森 崇のポートレート 鷺森 崇
IT基盤技術戦略室
2001年よりコンサルタントとして、産業・流通分野における先進的なIT技術の調査、コンサルティング、新規事業推進活動に従事。2014年よりITアナリストとしての活動に参画。専門はスマートデバイス関連技術、RFID(ICタグ)、ICカード、マーケティング・サイエンス、ロケーションテクノロジー、リテール業界のITサービスなど。
-
松崎 陽子
※組織名、職名は現在と異なる場合があります。