
AIの進化は止まらず、その影響は私たちの働き方、特に知的労働に大きな変革をもたらす可能性を秘めています。そこで本記事では、「生成AIと知的労働」をテーマにコンサルタントの西野が3回に分けてお届けしています。前回は、知的労働の一例としてIT部門の業務を取り上げ、生成AIが近い未来にどのように知的労働に変革を及ぼすのかについて説明しました。第2回の本記事では、企業の知的労働がAI活用により持続的に進化している状態に近づくために必要なITの備えについて説明します。
執筆者プロフィール

関西ITコンサルティング部 西野 浩明:
2001年、NRIに入社。15年超のシステム開発経験・プロジェクトマネジメント経験を活かして、ビジネス変革・業務改革を伴うシステム上流工程(構想、計画、システム調達)、インフラ構想(クラウド活用戦略、アーキテクチャーデザイン)、システム開発時のユーザー側活動(要件定義、開発標準化、業務移行、受入テスト)および大規模システムPMOなどのITコンサルティングに従事。
AIネイティブに近づくための2つの備え
ChatGPTをはじめとする生成AIの登場は、本格的なAI時代の幕開けと言えるでしょう。企業の成長戦略においては、戦略立案から実行に至るまで、そして生産から販売までのバリューチェーン全体にわたってAIを効果的に活用することが重要になります。そのためには、企業の知的労働がAI活用により持続的に進化している状態、つまり「AIネイティブ」に近づく必要があります。しかし、AIネイティブへの道のりはたやすいものではありません。今回から2回にわたり、生成AIと人間の知的な協働を通じて、AIネイティブに近づくための「ITの備え」と「組織の備え」について解説します。今回は「ITの備え」について詳しく解説します。「組織の備え」については次回の記事でご説明します。
AIネイティブに向けたITの備えには、「生成AI基盤の整備」と、「“Goodデータ”創出サイクルの構築」があります。
生成AI基盤の整備
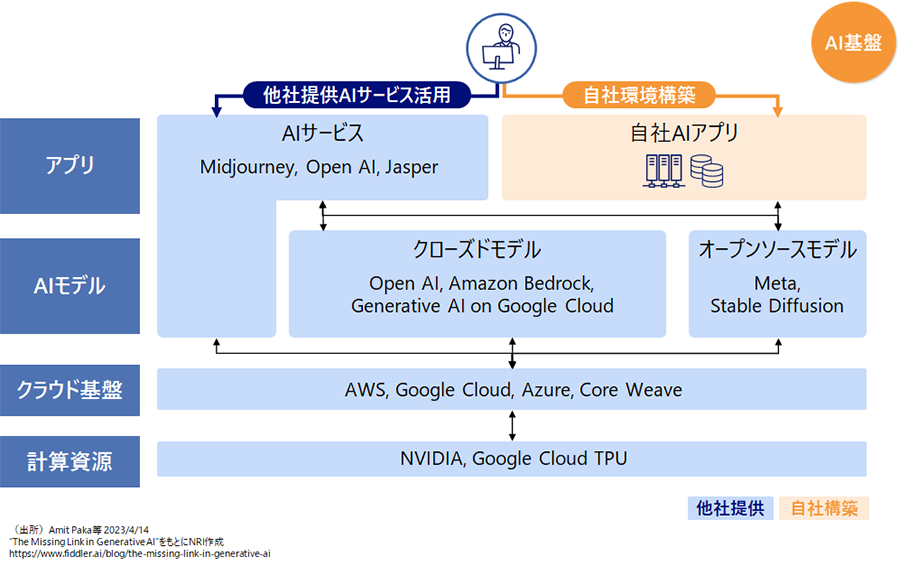
一般的に生成AI基盤は4層のレイヤー(計算資源、クラウド基盤、AIモデル、アプリ)によって構成されています(図1)。このうち下位3層は、OpenAIやMicrosoftなどのプラットフォーマーによって大規模な投資が行われ、整備が進められています。アプリ層については、これらのプラットフォーマーだけでなく、多数のスタートアップが様々なサービスを展開しています。そのため、多くの企業ではこれらのサービスを利用していくことが基本的なスタンスとなるでしょう。生成AIサービスは進化し続けるため、サービスの動向を把握しつつ、自社のニーズやビジネスユースケースを再整理し、最適なサービスを見極めて、プロンプトエンジニアリングを駆使してサービスを活用していくことが重要です。また、アプリ層については、自社特有のニーズやビジネスユースケースを満たすために、AIアプリを独自開発する場合もあります。このように、生成AI基盤の整備では、他社の生成AIサービスを利用する領域と、自社独自で環境構築する領域を組み合わせた「ハイブリッド型」のアプローチが可能となります。
図1 生成AI基盤の4層レイヤーとハイブリッド型アプローチ例
ここからは生成AIアプリの開発方法について解説します。生成AIアプリの開発には大きく以下2つの方式が考えられます(図2、3)。
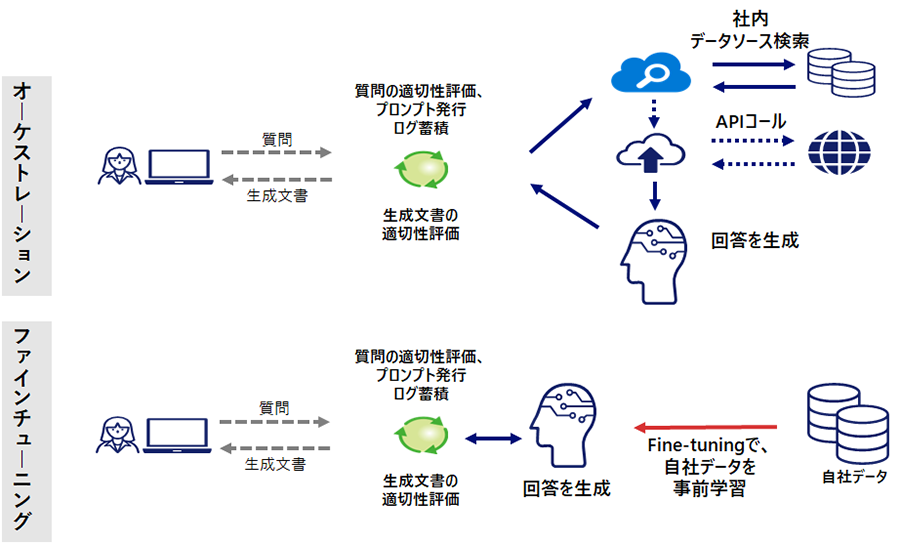
オーケストレーション:
生成AIへの複数の指示を制御して一括で実行させるオーケストレーションをアプリで開発します。
例えば、自社独自データを活用して顧客からの問い合わせに回答するというビジネスユースケースを想定した場合、「問い合わせ内容(生成AIに対するプロンプト)のチェック」「自社データの中から最適な情報の検索」「検索結果を要約・整理して回答生成」というような複数のタスクを連続的に実行する必要があります。この場合、OpenAIなどが提供する大規模言語モデルを適切に組み合わせて、プロンプトをテンプレート化し、PDFやCSVなどの自社データから問い合わせと関連性が高い情報を検索し、そして複数の回答案を統合するなどの推論ステップを経ることで、適切な回答を生成することが可能となります。このようなオーケストレーション方式のアプリ開発はLangChainなどのライブラリを活用することで実現できます。
ファインチューニング:
自社だけが持つデータを大規模言語モデルに追加学習させ、ファインチューニングすることで業務に特化したアプリを開発します。
例えば、金融アドバイザリーであるBloombergは、自社が蓄積した過去40年分の金融情報を大規模言語モデルに学習させ、自社サービスを高度化させるアプリの研究開発を行っています。今後は、自社の業務に特化した付加価値の高いファインチューニング方式のアプリ開発が一層盛んになると予想されます。ファインチューニングを行うと、「問い合わせ内容のチェック」は依然として必要ですが、「最適な自社データの検索」は不要になります。そして、チューニング次第で、より精度の高い回答を生成出来る可能性があります。最近では、MetaのLlama2のような商用利用可能なオープンソースの大規模言語モデルも登場しています。
図2 生成アプリ開発方式

図3 オーケストレーションとファインチューニングの方式イメージ
"Goodデータ"創出サイクルの構築
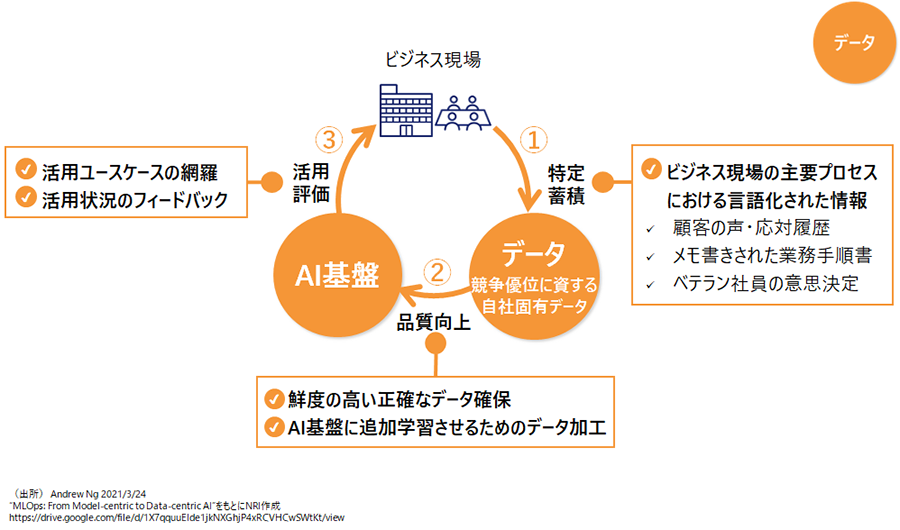
ビジネスの現場で培われる経験知やノウハウの多くは、従業員間のコミュニケーションを通じて伝達・蓄積され、個人に属する暗黙知として再利用されます。しかし、このアナログで人間に依存した知的労働のサイクルは、現代のAI技術、特に生成AIとの協働により大きく改善できる可能性があります。
ビジネスの現場で行われる日常のコミュニケーションや業務プロセスの多くは、言語のやり取り、つまり言語化された情報の交換しながら行われています。例えば、お客様との応対履歴やお客様からのフィードバック、業務手順が書かれたメモ、ベテラン社員の即時判断の根拠などの情報は有用な言語化データになり得ます。そこから、自社だけが持つ、自社の競争優位につながる固有データ、つまりデータを特定し、言語化されたデータとして蓄積するプロセスを設計します。
その後、データを生成AIモデルに追加学習させたり、データソースとして活用しますが、そのためにはデータの加工が不可欠です。例えば、最新のデータのみを使用する、業務観点で抜け漏れの無いデータにする、データサイズを適切な量に分割するなど、様々な工夫が求められます。
最後に、データの活用度をビジネス現場で評価し、その活用をさらに促進するために蓄積すべきデータを見直すことが必要です。この一連の活動を繰り返し行うことによって、データの価値を向上させていく活動が"Goodデータ"創出サイクルです(図4)。生成AIとの協働が進むにつれて、このサイクルの重要性は増していくでしょう。
理論的には、このような"Goodデータ"創出サイクルを構築し、回し続けることで、生成AIとの協働から生まれる価値は増大します。しかし、このような状態を実現するためには、様々な課題を解決する必要があります。
図4 "Goodデータ"創出サイクル
NRIによる実証実験と考察
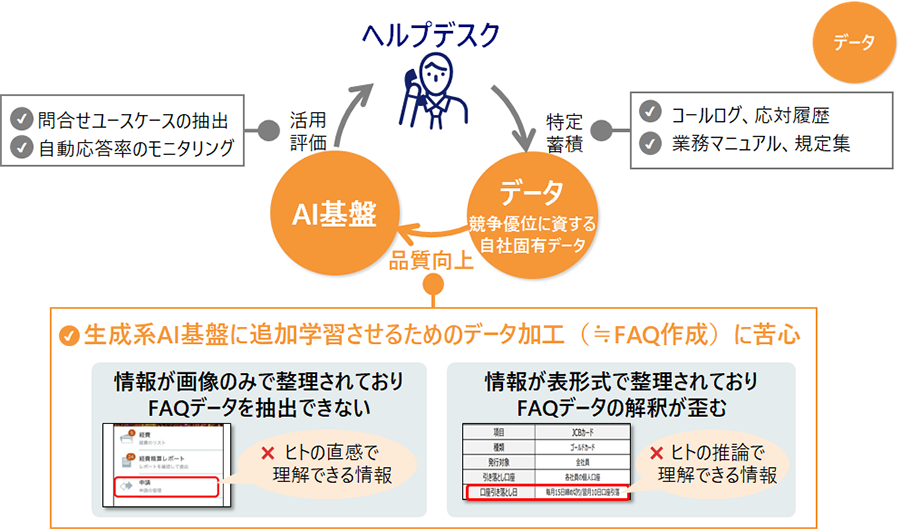
現在のビジネス環境で"Goodデータ"創出サイクルを実際に回すと、どのような問題が生じるかを検証するために、NRIにて実証実験を行いました。対象としたビジネスユースケースはヘルプデスクの問い合わせ対応業務です。生成AIモデルにテキストデータを学習させて、オペレーターの助けとなる情報を出力する生成AIアプリの構築を目指しました。
まず、ヘルプデスクの現場に存在する様々な情報の中から、競争優位につながるデータを特定するところから始めました。私たちが選んだデータはコールログと業務マニュアルでした。コールログは、実際の問い合わせと応対の内容であり、組織が暗黙知として持っているノウハウの源泉にあたります。業務マニュアルは、長年にわたって培われてきたノウハウがまとめられた形式知です。どちらの情報も、他の企業では得られない自社固有データです。
次に、これらのデータを生成AIモデルが学習できるように加工しようとしました。コールログは比較的容易に生成AIモデルに追加学習させられます。コールログのデータ量は非常に大きく、その中から有益な情報を抽出することは人間にとっては困難ですが、AIは大量のテキストデータから容易に学習することができます。もう一方の“Goodデータ”である業務マニュアルは、現場のノウハウが集約・整理された人間にとって分かりやすい文書ですが、生成AIモデルに追加学習させるには思いのほか大変でした。業務マニュアルには、生成AIモデルが容易に学習できるテキストデータだけでなく、画像などの非言語化データや、表形式で整理・情報圧縮されたテキストデータ多く含まれているためです。
画像や表にどのようなノウハウが埋め込まれているか人間なら一目で理解できますが、そのままでは生成AIには理解できません。生成AIモデルに学習させるためには画像や表をHTML形式に加工する必要がありました。さらに、画像や表の情報は、人間が推論して初めて正しく理解可能になるため、そのままテキスト化して生成AIモデルに追加学習させてもデータの解釈が歪むことが明らかになりました(図5)。
図5 NRIによる実証実験にて直面した問題
今回の実証実験を通じて得られた示唆は、次のようなことです。
「人間と生成AIの協働を加速させるためには、情報や知恵、ノウハウを、人間が理解しやすいだけでなく、AIにとっても理解しやすいように言語化してデータを蓄積していくことが極めて重要である」
生成AIとの協働が加速するAI時代では、人間の理解しやすさだけを重視した業務マニュアルではなく、海外製品のシステム操作マニュアルのように、単純に文字で表現された文書型の業務マニュアルの方が時代に求められているのだと思います。
ノウハウなど暗黙知の言語化・蓄積には時間がかかるため、企業がAIネイティブを目指すなら、そのための準備を早急に進める必要があります。
まとめ
今回は、企業がAIネイティブに近づくために必要な「ITの備え」について考察しました。「生成AI基盤の整備」と「"Goodデータ"創出サイクルの構築」は、その達成に欠かせない要素です。しかし、生成AIとの協働を加速させるためには「ITの備え」だけではなく、生成AIを取り入れる組織の意識改革や人材のスキルの転換などの「組織の備え」も必要となります。
次回の記事では、「組織の備え」として具体的にどのような備えが必要になるかについて解説します。
プロフィール
-
西野 浩明のポートレート 西野 浩明
関西システムコンサルティング部長
2001年、NRIに入社。15年超のシステム開発経験・プロジェクトマネジメント経験を活かして、ビジネス変革・業務改革を伴うシステム上流工程(構想、計画、システム調達)、インフラ構想(クラウド活用戦略、アーキテクチャーデザイン)、システム開発時のユーザー側活動(要件定義、開発標準化、業務移行、受入テスト)および大規模システムPMOなどのITコンサルティングに従事。
※組織名、職名は現在と異なる場合があります。