
自己紹介
こんにちは、野村総合研究所 認定データサイエンティストの清水です。
データ分析PoCや機械学習モデルを活用したシステム導入支援などを行っています。
今回は2023年7月に開催したウェビナーの内容を紹介します。データ・AI活用におけるデータ品質の重要性、そして改善方法を説明しています。詳しくはぜひ動画を視聴ください。
はじめに
AIの活用は日々進化しています。最近では生成AIが注目を集めていますが、わずか数か月で生成される文章や画像は格段に質が高くなっています。そうした時代背景の中、データ収集活用に着手している企業がかなり増えています。しかし、現実には多くの企業がAI開発で成果をあげられていません。その背景として、データの品質低下が大きく影響している可能性があります。
本記事では、AI活用のトレンドと、データ品質の重要性についてわかりやすく解説していきます。
AI活用のトレンド:データセントリックの到来
近年、「データセントリック」という概念が注目を浴びています。なぜデータが注目されているのでしょうか?それはAI開発が新たなステージを迎えつつあるためですが、その局面において「データ」が重要な意味をもつようになっているからです。
実は今、AI開発は難しい局面にたたされています。多くの企業がAI開発の中止を余儀なくされているのです。「AI白書2023」によると、半数以上の企業がAI開発を中止しています。その理由は、AIの理解不足や導入費用の高さなど、費用対効果の問題が挙げられますが、近年ではデータ関連の課題が増加しています。学習データの不足や整備の困難さがAI開発のボトルネックとなっているのです。
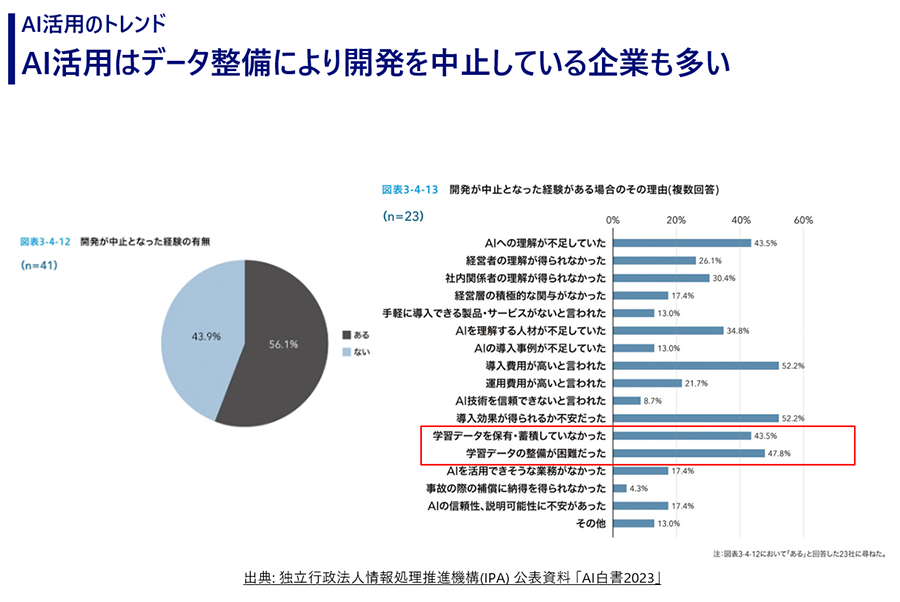
モデルセントリック開発からの転換
従来のAI開発では、データサイエンティストが中心となり、モデルやアルゴリズムの改良に注力してきました。しかし、データに関連する問題は、モデルの変更だけでは解決できないのです。
モデルやコードを固定したまま、継続的にデータの改善に取り組むことが求められるようになっています。データ品質の向上がビジネス成功の鍵となる、すなわちデータセントリック時代の到来です。
このような変化に伴い、重要な役割を果たすようになったのが、データエンジニアやデータを扱う現場の実務者です。彼らによるデータの品質改善が、AIの真の力を引き出すことになります。
データセントリックに対する専門家の見解
ここで、データセントリックのアプローチを裏付けるために、2人の専門家のコメントを紹介します。
一人目は、データセントリックを提唱するAI権威のアンドリュー氏です。氏は次のように述べています。「AIはコードとデータの両方で成り立つ重要な要素です。モデルの改良に加え、データの改善にも注力することが重要となります。
もう一人は、2012年に「データサイエンティストは21世紀で最もセクシーな職業」と言及したダベンポート氏です。氏は、今年に入り「データサイエンティストはセクシーな職業だったのか?」というレポートを発表しました。その中で彼は、「データサイエンスのコーディングではChatGPTの活用もあり、自動化が進んでいるが、クリーニングは自動化が進んでいない」と述べています。
AI開発において、モデル中心の開発が不要になったというわけではありません。しかし、データを改良せずに、モデルだけを改良する従来の開発スタイルは通用しなくなってきつつあります。今、求められているのは、データ品質を上げること、すなわち「Goodデータ」を確保することです。企業はデータセントリックな開発に優先的に取り組むことで、AI開発は新たな展開を実現することができるでしょう。
Goodデータのパワー:データ改良がもたらす劇的な影響
データがよくなる(Goodデータになる)とは、具体的にどのような効果をもたらすのでしょうか。実は、モデルの改良だけでは改善しにくかったAIの性能が、データの改良によって劇的に向上するケースがあります。ここでは、データセントリック論文で言及されている「鉄の表面不良検査」の例を通じて、その理由を説明します。
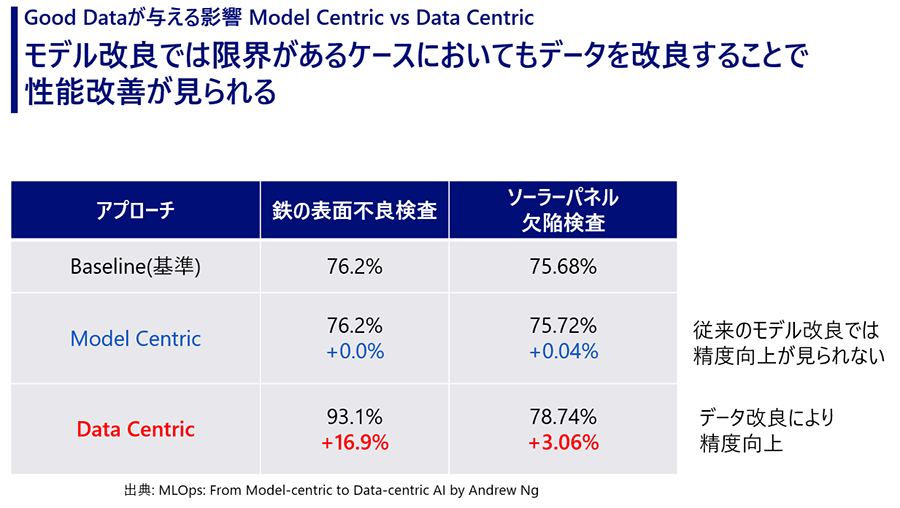
この図は、従来のモデルセントリックなアプローチと、データセントリックなアプローチで改良した場合の精度を比較しています。この例では、鉄の表面不良を検査するためのAIモデルを開発しました。モデルの改良による精度向上が限定的だった場合でも、データを変えていくことで明らかに向上が見られることがわかります。
また、Goodデータをどれだけ集めれば良いのかという点も注目です。実は、必ずしも大量のデータを集める必要はありません。次の例を見てみましょう。
以下の図は、データ量と精度の関係を示しています。横軸はデータ量を表し、縦軸は学習の精度を示す平均適合率(mAP:mean Average Precision)です。mAP値が1.0に近いほど、機械学習モデルの分類予測性能が高いことを意味します。

赤いラインは、元のデータにノイズが含まれる場合を示し、緑のラインはGoodデータに改良した場合を示しています。横軸の500というデータ量に注目して比較してみると、緑のラインの方が高い精度であることがわかります。
実は、500におけるデータの精度と同等の品質のデータを集めようとすると、3倍のデータ量が必要となります。つまり、Goodデータであれば、大量のデータを集める必要がなくなるのです。労力をかけずに品質を改善することで、精度向上を目指すことができます。
モデルの改良に限界がある場合でも、Goodデータの活用により劇的な精度向上が実現できます。さらに、その品質改善には大量のデータを集める必要はありません。従来のやり方ではデータの品質改善が得られなかったことに留意しながら、新たなアプローチでGoodデータを収集しましょう。
こうしたGoodデータの活用によって、ビジネスにおけるAIの性能向上と効率的な品質改善が実現されるのです。データセントリックなアプローチにより、AI活用の可能性がさらに広がると言えるでしょう。
- モデル改良はもう限界!
- AI活用で行き詰まりを感じている方へ
具体的に
どのようにGoodデータを収集していくか知りたい
方は、動画をぜひご視聴ください。
動画では、
データ収集の4つのポイントである「一貫性」「網羅性」「フィードバック」「サイズ」
について詳しく解説しています。これらのキーワードがどのようにデータの品質向上につながるのか、具体的な方法について事例を交えてご紹介しています。

プロフィール
-
清水 茂樹
※組織名、職名は現在と異なる場合があります。